[ad_1]
Coding is among the top uses of LLMs as per a Harvard 2025 report. Engineers and developers around the world are now using AI to debug their code, test it, validate it, or write scripts for it. In fact, with the way current LLMs are performing at generating code, soon they will be almost like a pair programmer for anyone who wishes to solve their coding problems. So far, Claude 3.7 Sonnet has held the title of being the best coding LLM to date. But recently, Google gave an update to their latest Gemini 2.5 Pro, and if benchmarks are to be believed, it beats Claude! So in this blog, we will put this claim to test. We will give same prompts to Gemini 2.5 Pro and Claude 3.7 Sonnet on various code-related tasks to see which LLM is the coding king.
Gemini 2.5 Pro vs Claude 3.7 Sonnet
Before we start with our model experimentation, let’s have a quick revision of these models.
What is Gemini 2.5 Pro?
Gemini 2.5 Pro is the long-context reasoner that DeepMind calls its premier multimodal AI model, being one under the Gemini 1.5 family, and fine-tuned to perform highly in text, code, and vision tasks. This model can reason over any kind of text of up to one million tokens in its context window: whole books, huge documents, or very long conversations precision and coherence. All of this makes it extremely useful for applications in the enterprise, scientific research, and mass content generation.
What truly sets Gemini 2.5 Pro apart is its native multimodality: it is the only other model that can understand and reason across different data types fairly easily-interpreting images, text, and soon, audio. It powers sophisticated features in Workspace and Gemini apps and developer tools through the Gemini API, with tight integration into the Google ecosystem.
What is Claude 3.7 Sonnet?
The newest mid-tier model in the Claude 3 family is Claude 3.7 Sonnet, intermediating between the smaller Haiku and flagship Opus models. Being “mid-tier” in nature, Claude 3.7 Sonnet attains or sometimes exceeds the performance of GPT-4 in some benchmarks like structured reasoning, coding assistance, and business analysis. It is very responsive and cheap, well-suited for developers and businesses who want advanced AI capabilities without the cost of top-end models.
A big selling point for Claude 3.7 Sonnet is the emphasis on ethical alignment and reliability that can be traced back to the Constitutional AI principles of Anthropic. Multimedia input support (text + image), long documents handling, summarization, Q&A, and ideation are all areas where it shines. Regardless of whether it is accessed via Claude.ai, the Claude API, or embedded into enterprise workflows, Sonnet 3.7 offers a nice trade-off between performance, safety, and speed, making it perfect for teams that need trustworthy AI at scale.
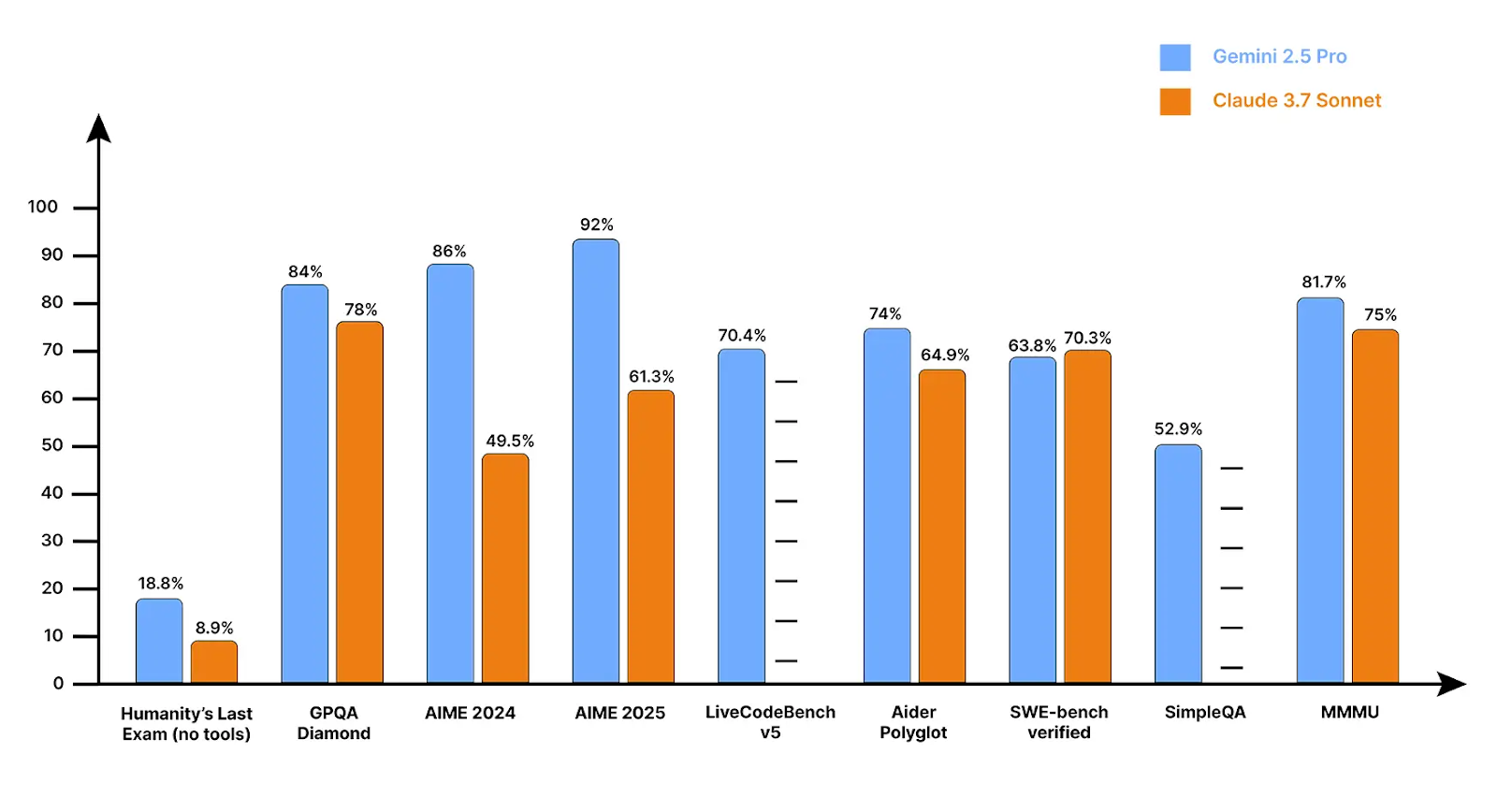
Gemini 2.5 Pro vs Claude 3.7 Sonnet: Benchmark Comparison
Gemini 2.5 Pro, regarded with general knowledge and mathematical reasoning benchmarks, while the Claude 3.7 Sonnet is a consistent victor when coding specific benchmarks come into the picture. Claude also scores well on measures of truthfulness, thus implying that Anthropic genuinely puts effort into lessening hallucinations.
| Benchmark | Winner |
|---|---|
| MMLU (general knowledge) | Gemini 2.5 Pro |
| HumanEval (Python coding) | Claude 3.7 Sonnet |
| GSM8K (math reasoning) | Gemini 2.5 Pro |
| MBPP (programming problems) | Claude 3.7 Sonnet |
| TruthfulQA | Claude 3.7 Sonnet |
For context handling, Gemini’s huge one-million token window coupled with its Google ecosystem, is an advantage when dealing with extremely large codebases, while Claude tends to respond faster with normal coding tasks.
Gemini 2.5 Pro vs Claude 3.7 Sonnet: Hands-On Comparison
Task 1: JavaScript Endless Runner game
Prompt: “Create a pixel-art endless runner in p5.js where a robotic cat dashes through a neon cyberpunk cityscape, dodging drones and jumping over broken circuits. I want to run this locally.”
Gemini 2.5 Pro Output
Claude 3.7 Sonnet Output
Response Review:
| Gemini 2.5 Pro | Claude 3.7 Sonnet |
|---|---|
| The code provided by Gemini 2.5 Pro seemed inadequate, like it went out of context, which didn’t work for us. | Claude 3.7 code offers a good animation game with amazing control functionality and features like quit and restart work properly, but sometimes the game ends automatically. |
Result: Gemini 2.5 Pro: 0 | Claude 3.7 Sonnet: 1
Task 2: Procedural Dungeon Generator in Pygame
Prompt: “Build a basic procedural dungeon generator in Python using pygame. The dungeon should consist of randomly placed rooms and corridors, and the player (a pixel hero) should be able to move from room to room. Include basic collision with walls.”
Gemini 2.5 Pro Output:
Claude 3.7 Sonnet Output:
Response Review:
| Gemini 2.5 Pro | Claude 3.7 Sonnet |
|---|---|
| The code given by Gemini 2.5 Pro offers a structured approach and has better control functionality. | Claude 3.7 has better animation with decent control, even though the pixel hero doesn’t respond when 2 keys are pressed simultaneously. |
Result: Gemini 2.5 Pro: 1 | Claude 3.7 Sonnet: 1
Task 3: Wildcard Pattern Matching Coding Problem
Prompt: “Give the solution to this problem in C++. Given an input string (s) and a pattern (p), implement wildcard pattern matching with support for “?’ and” where:
Give the solution to this problem in C++. Given an input string (s) and a pattern (p), implement wildcard pattern matching with support for “?’ and” where:
– ‘?’ Matches any single character.
– ” Matches any sequence of characters (including the empty sequence).
– The matching should cover the entire input string (not partial).
Example 1:
Input: s = “aa”, p = “a”
Output: false
Explanation: “a” does not match the entire string “aa”.
Example 2:
Input: s = “aa”, p = “*
Output: true
Explanation: ” matches any sequence.
Example 3:
Input: s = “cb”, p = “?a”
Output: false
Explanation: ‘?’ matches ‘c’, but the second letter is ‘a’, which does not match ‘b’.
Constraints:
0 <= s.length, p.length <= 2000
s contains only lowercase English letters.
p contains only lowercase English letters, ‘?’ or **.“
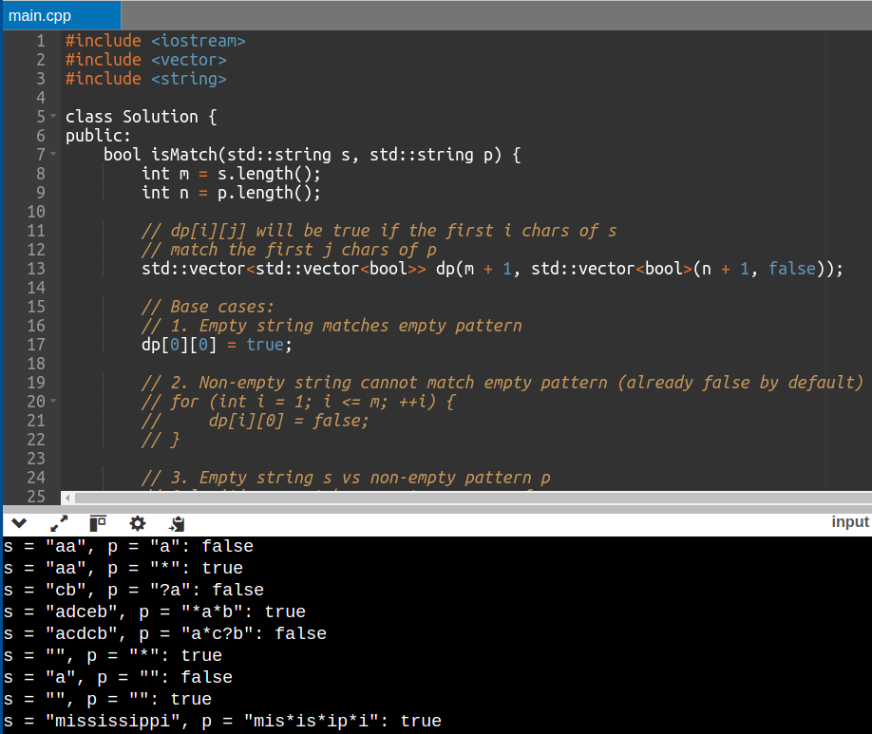
Gemini 2.5 Pro Output:
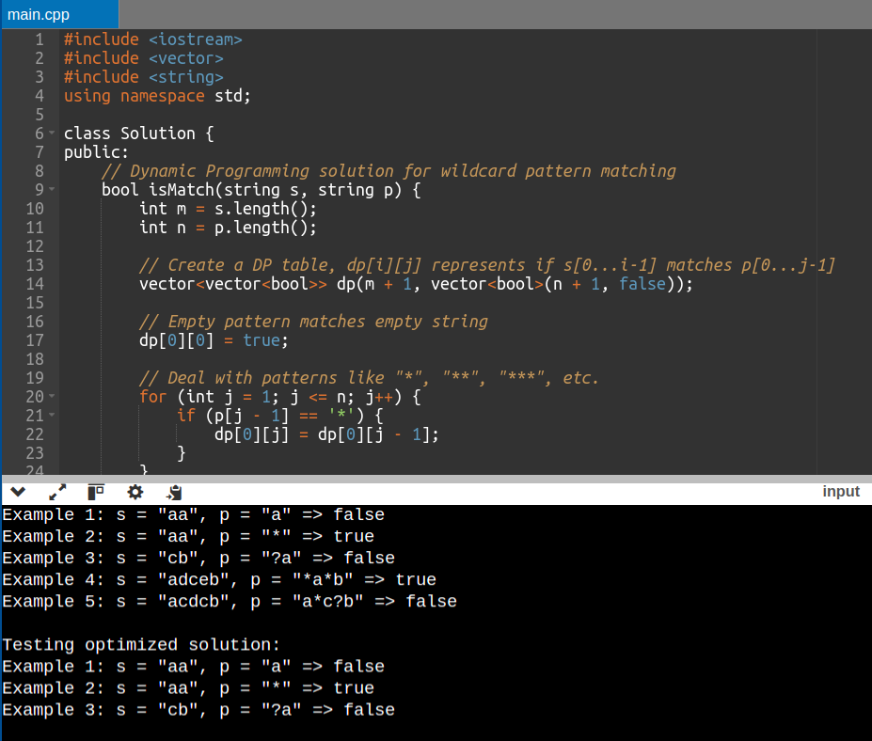
Claude 3.7 Sonnet Output:
Response Review:
| Gemini 2.5 Pro | Claude 3.7 Sonnet |
| Gemini 2.5 Pro shows its ability to excel in handling edge cases here. Its logic is clearer with better handling of wildcards, and it provides clarity in variable names as well. It proves to be more reliable as compared to Claude 3.7 Sonnet. It is suitable for real-world applications. | Claude 3.7 Sonnet uses dynamic programming for pattern matching, but it struggles with complex patterns like multiple ‘*’ wildcards which causes errors in some cases like ‘mississippi’. |
Result: Gemini 2.5 Pro: 1 | Claude 3.7 Sonnet: 0
Task 4: Shooter Game using Pygame
Prompt: “I need you to program a retro-style 2D side-scroller shooter game in Python using Pygame. The player would assume control of a spaceship whose lasers destroy incoming alien ships. Score tracking would be implemented, as well as some basic explosion animations.”
Gemini 2.5 Pro Output:
Claude 3.7 Sonnet Output:
Response Review:
| Gemini 2.5 Pro | Claude 3.7 Sonnet |
| It was presented as a minimal but functional implementation. The spaceship would move and shoot, yet alien collision detection was buggy. Scores are inconsistently updated. No explosion effects were added. | This would prove to be a fully functioning and polished game, with smooth movement, intuitive laser collisions, and score tracking, augmented with satisfying explosion animations. Controls felt smooth and visually appealing. |
Result: Gemini 2.5 Pro: 0 | Claude 3.7 Sonnet: 1
Task 5: Data Visualisation Application
Prompt: “Create an interactive data visualization application in Python with Streamlit that loads CSVs of global CO₂ emissions, plots line charts by country, allows users to filter on year range, and plots the top emitters in a bar chart.”
Gemini 2.5 Pro Output:
Claude 3.7 Sonnet Output:
Response Review:
| Gemini 2.5 Pro | Claude 3.7 Sonnet |
| Creating a clean interactive dashboard with filtering and charts. Charts are labeled well; Streamlit components, e.g., sliders and dropdowns, worked great together. | Claude 3.7 Sonnet also delivered the dashboard that worked, but was lacking interactivity in filtering. The bar chart remained static, and some charts were missing legends. |
Result: Gemini 2.5 Pro: 1 | Claude 3.7 Sonnet: 0
Comparison Summary
| Task | Winner |
|---|---|
| JavaScript endless runner game | Claude 3.7 Sonnet |
| Procedural Dungeon Generator Pygame | Both |
| Wildcard pattern matching coding problem | Gemini 2.5 Pro |
| Shooter game using Pygame | Claude 3.7 Sonnet |
| Data Visualisation Dashboard Application | Gemini 2.5 Pro |
Gemini 2.5 Pro vs Claude 3.7 Sonnet: Choose the Best Model
After experimenting and testing both models on different coding tasks, the “Best” choice depends on your specific needs.
You can choose Gemini 2.5 Pro when:
- You require the one-million token context window
- You’re integrating with Google Products
- Working with algorithms and Data visualization
You can choose Claude 3.7 Sonnet when:
- Your top priority is code reliability
- Development of games or interactive applications is needed
- The efficiency of the API cost is of greater importance
Both models justify their subscription pricing of $20 per month for professional developers. Losing time to debug, generate code, or just solve problems will wipe out any revenue earned. Whenever I need to code for the day, I tend to go with Claude 3.7 Sonnet because it generates interactive applications code better but when it comes to big datasets or documentation, Gemini’s context window might be the best for me.
Also Read:
Conclusion
The task comparison between Gemini 2.5 Pro and Claude 3.7 Sonnet revealed that there’s no clear overall winner, resulting in a tie between them as each model has distinct strengths and weaknesses for different coding tasks. While these models continue to evolve, they are becoming a must-have for every developer, not to replace human programmers but rather to multiply their productivity and capabilities manyfold. This decision between Gemini 2.5 Pro and Claude 3.7 Sonnet should be dictated only by what your project requires, not by what is considered “better”.
Let me know your thoughts in the comment section below.
![]()
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]
Login to continue reading and enjoy expert-curated content.
[ad_2]